
NVIDIA GEFORCE RTX 2080 TI圖形卡|,官方NVIDIA RTX 2080 TI,2080,&2070規格,價格,發行日期| GamersNexus-遊戲PC構建和硬件基準測試
2080 TI發布日期
但是,該消息的更大方面是NVIDIA專有的高速緩存連貫的GPU互連NVLINK將會使用消費卡. GeForce GTX卡將通過NVLink實現SLI,每張卡之間有2個NVLINK頻道. 在全雙工帶寬的50GB/秒組合中 – 意味著每個方向都有50GB的帶寬 – 這是對NVIDIA以前的HB-SLI鏈接的重大升級. 這是NVLink的其他功能優勢,尤其是Cache Coohrence. 所有這些都在一個重要的時刻,因為GPU間的帶寬要求不斷上升.
NVIDIA GEFORCE RTX 2080 TI圖形卡
改裝GEFORCE RTX 2080 TI支持22GB GDDR6內存
Teclab與GeForce RTX 2080 TI打破3GHz GPU時鐘屏障
有傳言稱NVIDIA退休GeForce RTX 2080(TI/SUPER)和GEFORCE RTX 2070(SUPER)圖形卡很快
MSI OUTS GEFORCE RTX 2080 TI遊戲Z帶16 Gbps Gddr6內存
NVIDIA宣布GeForce RTX 2080 TI“ Cyberpunk 2077 Edition”
華碩展示GeForce RTX 2080 Ti Rog Strix White Edition
Gigabyte使用RTX 2080 TI啟動Aorus遊戲盒
Galax GeForce RTX 2080 TI HOF 10週年版發現
MSI RTX 2080 TI Lightning 10週年版圖
MSI挑選GeForce RTX 2080 TI Lightning 10週年版
(PR)MSI宣布GeForce RTX 2080 TI Lightning Z
evga geforce RTX 2080 Ti Kingpin Edition是混合動力
MSI GEFORCE RTX 2080 TI閃電圖
ASUS展示ROG GEFORCE RTX 2080 TI矩陣
五顏六色的geforce rtx 2080 ti igame kudan smiles for Camera
MSI挑逗碳纖維GeForce RTX 2080 Ti Lightning Z
Zotac GeForce RTX 2080 Ti ArcticStorm將在CES 2019上首次亮相
MSI GEFORCE RTX 2080 TI Lightning Z PCB圖
五顏六色的發射Geforce RTX 2080(TI)RNG版本帶有全彩色LCD
(PR)Inno3D宣布Geforce RTX Ichill Frostbite系列
evga戲弄GeForce RTX 2080 Ti Kingpin
GEFORCE RTX 2080 TI AORUS TURBO準備GEFORCE RTX
NVIDIA捆綁式戰場V與GeForce RTX免費
(PR)Manli宣布Geforce RTX 2080 TI和2070與鼓風機迷
新卡報告#21:RTX RGB版本
Inno3D將GeForce RTX卡變成巨型RGB聖誕樹
MSI宣布GeForce RTX 2080(TI)Sea Hawk(EK)X系列
千兆字節挑逗GeForce RTX 2080(TI)AORUS圖形卡
NVIDIA GEFORCE RTX 2080 TI&RTX 2080評論綜述
TechPowerup解釋了Turing A和非A GPU變體之間的區別
NVIDIA GEFORCE RTX 2080 TI和RTX 2080“官方”表演揭幕了
Nvidia Turing Architecture的新功能
NVIDIA更改GeForce RTX 2080評論日期至9月19日
NVIDIA GEFORCE RTX 2080評論將於9月17日上線
EVGA揭開水電銅和混合型GeForce RTX型號
- 2025 GEFORCE 50 TBA
- 2023 GeForce 40手機
- 2022 GEFORCE 40
- 2021 GeForce 30手機
- 2020年GEFORCE 30
- 2019 GeForce 16
- 2019 GeForce 16手機
- 2018 GeForce 20
- 2018 GeForce 20手機
- 2016 GeForce 10
- 2016 GeForce 10手機
- 2014 GeForce 800手機
- 2014 GeForce 900
- 2014 GeForce 900手機
- 2013 GeForce 700
- 2013 GeForce 700手機
- 2012年GEFORCE 600
- 數據中心 /特斯拉
- Tegra
- 工作站 / Quadro
- Geforce MX
- 泰坦RTX
- GeForce RTX 2080 TI
- GeForce RTX 2080超級
- Geforce RTX 2080
- GeForce RTX 2070超級
- GeForce RTX 2070
- GeForce RTX 2060超級
- GeForce RTX 2060 12GB
- GeForce RTX 2060
- GeForce MX250
- 3D堆疊
- 配件
- 公告
- 蘋果
- 手臂
- 人工智慧
- 汽車行業
- 基準
- 商業與市場
- 中國圖形
- 概念
- 連接性
- 內容創建
- 冷卻技術
- 加密貨幣
- 定制項目
- 交易
- 顯示和監視器
- 事件
- 外部GPU和外殼
- 外部評論
- 極端超頻
- 財務業績
- 鑄造廠
- 遊戲捆綁和交易
- 遊戲要求
- 遊戲流
- 遊戲
- 遊戲機
- 遊戲硬件
- 圖形
- 圖形API
- 訪談
- Linux
- 記憶技術
- 迷你/sff/nuc PC
- 行動裝置
- 改裝
- 主板
- 筆記本
- 專利與研究
- PC案件
- PCI Express
- 人們
- 電源
- 預建系統
- RISC-V
- 安全
- 軟件和驅動程序
- 貯存
- 超級分辨率
- 超級計算(HPC)
- 視頻編碼
- 病毒故事
- 虛擬現實
- 水冷
- 2025 Radeon 8000 TBA
- 2023 Radeon 7000手機
- 2022 Radeon 7000
- 2021 Radeon 6000手機
- 2020 Radeon 6000
- 2019 Radeon 5000
- 2019 Radeon 5000手機
- 2017 Radeon 500
- 2017 Radeon 500手機
- 2016 Radeon 400
- 2016 Radeon 400手機
- 2015 Radeon 300
- 2015 Radeon 300手機
- 2014 Radeon 200手機
- 2013 Radeon 200
- 萊登本能
- Radeon Pro
- 區塊鏈計算
- 2025 GEFORCE 50 TBA
- 2023 GeForce 40手機
- 2022 GEFORCE 40
- 2021 GeForce 30手機
- 2020年GEFORCE 30
- 2019 GeForce 16
- 2019 GeForce 16手機
- 2018 GeForce 20
- 2018 GeForce 20手機
- 2016 GeForce 10
- 2016 GeForce 10手機
- 2014 GeForce 800手機
- 2014 GeForce 900
- 2014 GeForce 900手機
- 2013 GeForce 700
- 2013 GeForce 700手機
- 2012年GEFORCE 600
- 數據中心 /特斯拉
- Tegra
- 工作站 / Quadro
- Geforce MX
- 2025 ARC DRUID TBA
- 2024 ARC天體TBA
- 2023 ARC BATTLEMAGE TBA
- 2022 ARC煉金術士
- 2022英特爾數據中心HPC TBA
- 2021英特爾數據中心HP TBA
- 2020英特爾XE-LP
- Arc Pro
2080 TI發布日期
官方NVIDIA RTX 2080 TI,2080和2070規格,價格,發布日期
史蒂夫·伯克(Steve Burke)於2018年8月20日下午3:00出版

更新: 添加了對SM / CUDA核心編號的更正,現在已經洩漏了完整的詳細信息.
Nvidia今天宣布了新的Turing視頻卡,包括RTX 2080 TI,RTX 2080和RTX 2070. 這些卡通過升級但熟悉的Volta體系結構向前推進,對SMS和內存進行了一些更改. 新的RTX 2080和2080 TI船首先帶有參考卡,以及合作夥伴卡 在很大程度上同時(有一些更高級的型號在1個多個月後出現), 取決於哪個伴侶. 董事會合作夥伴直到與媒體相同的時間都沒有獲得定價甚至卡命名. 請注意,我們最初聽到了合作卡上1-3個月的延遲,但這似乎僅適用於剛剛進入生產的高級模型. 大多數三扇形型號應在同一日期提供.
另一個主要考慮點是Nvidia決定使用雙軸參考卡,消除了低端夥伴卡的大部分價值. 遠離鼓風機的參考卡和雙扇卡卡,最立即影響董事會的合作夥伴,這可能會導致NVIDIA慢慢爬行,從而擴大其直接消費者的銷售並繞開合作夥伴. RTX 2080 TI的價格為1200美元,將於9月20日推出,2080年為800美元(和9月20日),而2070年為600美元(TBD發布日期).
NVIDIA RTX 2080 TI和2080規格
比較新GPU時,人們犯的最大錯誤之一就是談論“核心計數.”這是錯誤的,原因有一些,其中之一是核心核心性能並非相同. 從開普勒到帕斯卡爾,每瓦的總體效率的增長超過30%,並且僅在核心計數之間進行線性比較,這不適用於此. 另外,庫達核心不是 真的 無論如何,內核:它們是浮點單位. SM將與標准定義更類似於核心,該定義要求核心能夠獲取和解碼說明,執行它們,閱讀和從寄存器和緩存中讀取和編寫數據,以及計算結果. NVIDIA的浮點單元可以計算結果,但無法做其他事情.
所有這一切的觀點是嚴格的帕斯卡爾與. 圖靈核心比較需要考慮建築差異,這可能會改變“核心”的表現如何. 人們上次陷入同一陷阱.
NVIDIA RTX 2080 TI,2080和2070創始人版規格
NVIDIA的新RTX 2080 TI託管4352浮點單元,RTX 2080非TI託管2944 FPU. Nvidia堅持每個流的多處理器64 fpu,這將2080 Ti置於68 SMS,2080在46 SMS處. NVIDIA重新設計了此GPU的SM架構,因此我們對所有細節都不是積極的.
新的GPU也轉移到GDDR6,這是一個預期的轉變. 目前,GDDR6的bom成本比GDDR5高約20%,但該成本會隨著時間而下降. GDDR6允許在RTX 2080和2080 Ti上的每個引腳吞吐量最少14Gbps,這是8GBPS上值得注意的提升和前幾代的10Gbps吞吐量. GDDR6也可以提高每引腳16Gbps,但對新GPU沒有立即的承諾. 我們尚不確定GDDR6的內存計時影響. 2080 TI將在352位內存總線上託管11GB的GDDR6,並在620GB/s附近的內存帶寬. RTX 2080將在256位接口上託管8GB的GDDR6,因此允許448GB/S內存帶寬.
| RTX 2080 TI | RTX 2080 | RTX 2070 | |
| fp32 fpus(“ cuda cores”) | 4352 | 2944 | 2304 |
| 流多處理器 | 68 | 46 | 36 |
| 核心時鐘 /提升時鐘 | 1350/1545 FE:1635MHz | 1515/1710 FE:1800MHz | 1410/1620 FE:1710MHz |
| 內存界面 | 352位 | 256位 | 256位 |
| 內存容量 | 11GB | 8GB | 8GB |
| GDDR6速度 | 14Gbps | 14Gbps | 14Gbps |
| 內存帶寬 | 616GB/s | 448GB/s | 448GB/s |
| sli | NVLINK 2路 | NVLINK 2路 | TBD |
| TDP | 〜265〜285W | 〜250-260W | 175-185W |
| 價格 | $ 1,200 或$ 1000* | $ 800 或$ 700* | $ 600 或$ 500* |
| 發布日期 | 9月. 20,2018 | 9月. 20,2018 | TBD |
*價格來源:NVIDIA的網站. 筆記: 我們還聽說過價格(也許對於非FE卡? 還是在NVIDIA中只是溝通不暢?)1070美元也可能為$ 500,2080美元的$ 700,2080 Ti的$ 1000. 我們認為這可能是Fe vs. 參考,但這也可能是NVIDIA團隊的溝通不暢. 目前尚不清楚.
NVIDIA宣布GeForce RTX 20系列:RTX 2080 TI&2080在9月. 10月20日,RTX 2070

NVIDIA的Gamescom 2018主題演講剛剛結束,並且自從上個月宣布以來,Nvidia已準備好啟動其下一代GeForce Hardware. 在活動中宣布,並從9月20日開始發售是NVIDIA的GEFORCE RTX 20系列,該系列即將成為當前的Pascal驅動的GeForce GTX 10系列. 基於NVIDIA的新型Turing GPU架構,並基於TSMC的12nm“ FFN”過程,NVIDIA具有崇高的目標,希望推動遊戲的呈現方式以及如何評估PC視頻卡的整個範式轉變. 首席執行官詹森·黃(Jensen Wang)稱圖靈·恩維迪亞(Turing Nvidia)自2006年的特斯拉GPU建築(G80 GPU)以來最重要的GPU架構,從特徵的角度來看,很明顯,他並沒有誇大其詞。.
傳統上,NVIDIA馬stable中的第一張卡片是高端卡片. 但是,在與傳統相當大的突破中,我們不僅要在發佈時獲得X80和X70卡,而且還要獲得X80 Ti卡. 意思是GeForce RTX 2080 TI,RTX 2080和RTX 2070都將在一個月內沿著街頭上映. NVIDIA的產品堆棧在這裡保持不變,因此RTX 2080 Ti仍然是他們的旗艦卡,而RTX 2080是他們的高端卡,然後RTX 2070略便宜的卡片可以吸引愛好者而無需破壞銀行的愛好者.
這三張卡將在接下來的兩個月內推出. 首先將是RTX 2080 TI和RTX 2080,該2080將於9月20日啟動 . RTX 2080 TI的合作卡的起價為999美元,而RTX 2080的起價為699美元. 同時,RTX 2070將於10月的某個時候推出,合作夥伴卡起價為499美元. 在歷史的基礎上,所有這些價格均高於上一代,而120美元至300美元之間. 同時,NVIDIA自己的參考質量創始人版卡再次又回來了,這些卡將攜帶100到200美元的高價.
不幸的是,NVIDIA已經在這裡進行預訂,因此,如果消費者想從第一批次中搶購卡,就必須進行“盲購買”. Nvidia提供了令人驚訝的有關性能的信息,我們建議等待可信賴的第三方評論(我.e. 我們),但是我不得不承認,我不認為這是在街上的評論會有太多庫存.
| NVIDIA GEFORCE規範比較 | ||||||
| RTX 2080 TI | RTX 2080 | RTX 2070 | GTX 1080 | |||
| 庫達核心 | 4352 | 2944 | 2304 | 2560 | ||
| 核心時鐘 | 1350MHz | 1515MHz | 1410MHz | 1607MHz | ||
| 提升時鐘 | 1545MHz | 1710MHz | 1620MHz | 1733MHz | ||
| 內存時鐘 | 14Gbps gddr6 | 14Gbps gddr6 | 14Gbps gddr6 | 10Gbps gddr5x | ||
| 內存總線寬度 | 352位 | 256位 | 256位 | 256位 | ||
| vram | 11GB | 8GB | 8GB | 8GB | ||
| 單精度perf. | 13.4個Tflops | 10.1個Tflops | 7.5個Tflops | 8.9個Tflops | ||
| 張量. | 440T行動 (int4) | ? | ? | N/A。 | ||
| 雷·佩奇(Ray Perf). | 10灰色/s | 8灰色/s | 6個灰色/s | N/A。 | ||
| “ RTX-OPS” | 78t | 60t | 45t | N/A。 | ||
| TDP | 250W | 215W | 175W | 180W | ||
| GPU | 大圖靈 | 不願透露姓名的圖靈 | 不願透露姓名的圖靈 | GP104 | ||
| 晶體管計數 | 18.6b | ? | ? | 7.2b | ||
| 建築學 | 圖靈 | 圖靈 | 圖靈 | 帕斯卡 | ||
| 製造過程 | TSMC 12nm“ FFN” | TSMC 12nm“ FFN” | TSMC 12nm“ FFN” | TSMC 16nm | ||
| 發射日期 | 2018年9月20日 | 2018年9月20日 | 10/2018 | 2016年5月27日 | ||
| 啟動價格 | 零售商:$ 999 創始人$ 1199 | 零售商:$ 699 創始人$ 799 | 零售商:$ 499 創始人$ 599 | 零售商:$ 599 創始人$ 699 | ||
NVIDIA的圖靈建築:RT&Tensor核心
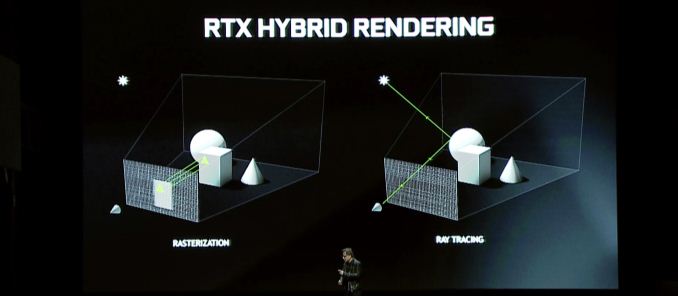
那麼圖靈帶來什麼? 整體上的字幕功能是混合渲染,它結合了射線追踪與傳統的柵格化,以利用這兩種技術的優勢. 該公告本質上是今年早些時候NVIDIA的RTX公告的延續,因此,如果您認為該公告有點稀疏,那麼這就是故事的其餘部分.
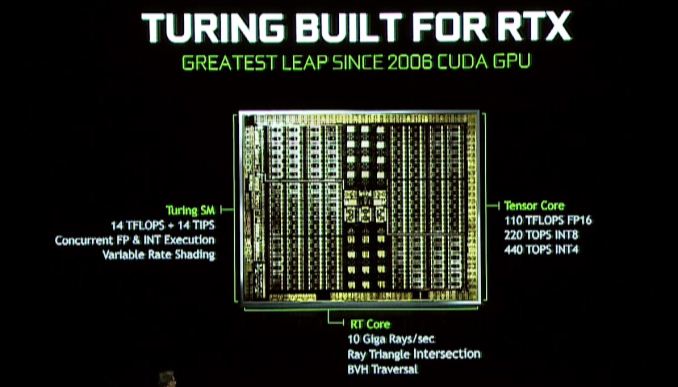
這裡的最大變化是,NVIDIA將包括更多的射線跟踪硬件和圖靈,以便提供更快,更有效的硬件射線跟踪加速度. NVIDIA所說的RT核心是Turing Architecture的新手,目前我們尚未完全了解其基礎,而是充當專門的射線追踪處理器. 這些處理器塊加速了射線三角形交集檢查和邊界量層次結構(BVH)操作,後者是存儲射線跟踪對象的非常流行的數據結構.
NVIDIA指出,最快的GeForce RTX部分每秒可以施放100億(GIGA)的光線,與不加封閉的Pascal相比,射線跟踪性能提高了25倍.
圖靈架構也載有來自Volta的張量芯,實際上,這些結構甚至在Volta上得到了增強. 張量芯是多個NVIDIA計劃的重要方面. 除了加快射線的追踪外,Nvidia在Turing Bags Tricks中的另一個工具是減少場景中使用AI DeNosing清理圖像所需的射線量,這是Tensor corex excel. 當然,這並不是唯一的特徵張核心核心是- Nvidia的整個AI/神經網絡帝國幾乎都建立在它們上- 因此,儘管不是Gamescom人群的主要重點,但這也證實了NVIDIA最強大的神經網絡硬件將會到來到更廣泛的GPU.
從一般而言,有趣的是,儘管有這些個人加速,但Nvidia的總體表現並不那麼極端. 總而言之,該公司承諾將獲得6倍的性能提升與帕斯卡爾(Pascal),這並不能指定哪些部分. 時間會證明這是否是現實的評估,即使是RT核心,射線追踪一般仍然是資源豬.
至於遊戲問題,混合渲染的好處可能是重要的,但這將在很大程度上取決於開發人員如何選擇使用它. 從性能的角度來看,我不確定這裡有太多要說的話,那是因為射線跟踪和混合渲染最終是提高渲染質量的功能,而不是提高當今算法的性能. 當然,如果您嘗試在今天的GPU上進行射線追踪,那將非常慢 – 結果是令人難以置信的加速 – 但是沒有人在當前硬件上使用慢速路徑跟踪系統. 因此,混合渲染是用更準確的渲染方法代替當前柵格技術的近似值和黑客. 換句話說,少了“偽造”,而是“做到”.透明

反過來,這些質量好處通常是在照明,陰影和反射的聚集. 這三個功能固有地基於光的屬性,其簡單的術語以射線的形式移動,並且到現在為止,各種算法一直在偽造所涉及的作品或提前“預釀造”場景. 儘管目前的算法相當不錯,但它們仍然不太準確. 因此有明確的改進空間.


NVIDIA尤其圍繞著全球照明,這是更艱鉅的任務之一. 但是,還有其他有益的照明方法,更不用說這些點亮對象的反射和陰影. 說實話,這是單詞是一個糟糕的工具。很難描述射線追踪的陰影看起來比帶PCS的假陰影更好,或者在預先烘焙的照明上實時照明. 這就是為什麼視頻卡公司NVIDIA將比以往任何時候都更加努力地推動所有這一切的視覺方面.
總的來說,混合渲染是GeForce RTX 20系列的Lynchpin功能. 通過他們的Gamescom和Siggraph演講,很明顯,NVIDIA已經投入了大量投資,他們敢打賭,在未來幾年中,Geforce品牌的成功在這項技術上. RT內核和張量核是半固定功能硬件;它們不能用於柵格化,分配給它們的晶體管是晶體管,這些晶體管本來可以專用於更多的柵格化硬件. 因此,Nvidia通過走混合渲染路線,而不是建造更大的Pascal,從而在這裡取得了極大的重大舉措.
結果,NVIDIA正在嘗試改變消費者渲染的範式,我們才真正在2001年和2002年之前引入Pixel和Vertex著色器(DX8&DX9 ERA TECH)才真正看到它。. 這就是為什麼Microsoft的DirectX Raytracing(DXR)倡議如此重要,NVIDIA的其他開發商和消費者計劃也是如此. NVIDIA需要在將柵格化與射線追踪混合以提供更好的圖像質量的願景上出售消費者和開發人員. 不僅如此,他們還需要放鬆開發人員的想法,因為摩爾定律繼續放慢腳步和固定功能硬件,因此可以使用更專業的固定功能單元,成為實現更高效率的手段.
NVIDIA並沒有在混合渲染上打賭農場,但他們從來沒有試圖以這種方式轉移市場. 因此,如果Nvidia似乎是在混合渲染和射線追踪上都非常關注的,那是因為它們是. 這是他們對未來的願景,現在他們需要讓其他所有人加入.
Turing SM:專用INT內核,統一緩存,可變速率陰影
除了專用的RT和Tensor內核外,Turing Architecture流式多處理器(SM)本身也在學習一些新技巧. 特別是在這裡,它繼承了Volta的更新穎的變化之一,它看到整數岩心分離為自己的塊,而不是成為浮點Cuda核心的方面. 這裡的優勢 – 至少和我們在Volta中看到的一樣多 – 它加快了地址生成並融合乘以添加(FMA)性能,儘管與圖靈的許多方面一樣,它可能還有更多被用來的)比我們今天看到的.
Turing SM還包括NVIDIA所說的“統一的高速緩存體系結構”.”當我仍在等待Nvidia的官方SM圖時,尚不清楚這是否與我們與Volta看到的統一相同 – 在L1 Cache與共享內存合併的地方,或者NVIDIA是否已邁出了一步. 無論如何,Nvidia說它提供了“上一代”的帶寬的兩倍,這還不清楚Nvidia是否表示Pascal或Volta(後者更有可能).
最後,在Siggraph Turing新聞稿中也藏起來是對可變速率陰影的支持. 這是一種相對年輕且即將到來的圖形渲染技術,有關NVIDIA如何實施它的信息有限(特別是). 但是,在很高的水平上,聽起來像下一代NVIDIA的多分辨率陰影技術,這使開發人員可以在各種有效的分辨率下呈現屏幕的不同區域,以便將質量(並呈現時間)集中到該領域這是最有益的.
餵野獸:GDDR6支持
由於GPU所使用的內存是由外部公司開發的,因此這裡沒有大秘密. JEDEC及其3大會員三星,SK Hynix和Micron都在開發GDDR6的內存,成為GDDR5和GDDR5X的繼任者,Nvidia Ha確認Turing將支持它. 根據製造商的不同,第一代GDDR6通常被提升為每引腳的記憶帶寬最多可提供16Gbps,這是NVIDIA晚期GDDR5卡的2倍,比NVIDIA最新的GDDR5X卡快40%.
| GPU內存數學:gddr6 vs. HBM2 vs. GDDR5X | ||||||||
| NVIDIA GEFORCE RTX 2080 TI (GDDR6) | NVIDIA GEFORCE RTX 2080 (GDDR6) | Nvidia Titan v (HBM2) | NVIDIA TITAN XP | NVIDIA GEFORCE GTX 1080 TI | NVIDIA GEFORCE GTX 1080 | |||
| 總容量 | 11 GB | 8 GB | 12 GB | 12 GB | 11 GB | 8 GB | ||
| B/W每針 | 14 GB/S | 1.7 GB/S | 11.4 Gbps | 11 Gbps | ||||
| 芯片容量 | 1 GB(8 GB) | 4 GB(32 GB) | 1 GB(8 GB) | |||||
| 不. 籌碼/kgsd | 11 | 8 | 3 | 12 | 11 | 8 | ||
| 每芯片/堆棧B/W | 56 GB/S | 217.6 GB/S | 45.6 GB/S | 44 GB/S | ||||
| 公交寬度 | 352位 | 256位 | 3092位 | 384位 | 352位 | 256位 | ||
| 總B/W | 616 GB/S | 448GB/s | 652.8 GB/S | 547.7 GB/S | 484 GB/S | 352 GB/S | ||
| DRAM電壓 | 1.35 v | 1.2 V(?) | 1.35 v | |||||
相對於GDDR5X,GDDR6不如過去的記憶幾代那樣大,因為GDDR6的許多創新已經融入GDDR5X中. 儘管如此,與HBM2相比,對於非常高的用例. 這裡的原理更改包括較低的工作電壓(1.35V),內部內存現在分為每個芯片的兩個內存通道. 對於標準的32位寬芯片,這意味著一對16位存儲通道,對於256位卡上的總共16個這樣的頻道. 雖然這又意味著有很多渠道,但GPU也可以很好地利用它,因為它們是一開始都是平行的設備.

NVIDIA的一部. 我們知道NVIDIA專門使用三星的GDDR6作為Quadro RTX卡 – 大概是因為它們需要密度 – 但是對於GeForce RTX卡,該字段應向所有內存製造商開放. 儘管從長遠來看,這留下了兩種途徑,可以使用更高容量的卡:提高到16GB密度芯片,或者使用他們現在使用的8GB芯片進行翻蓋.
賠率和目的:NVLink Sli,Virtuallink和8K HEVC
儘管NVIDIA的Gamescom演示文稿本身並未提及,但NVIDIA的GeForce 20系列網站證實SLI將再次用於一些高端GeForce RTX卡. 具體而言,RTX 2080 TI和RTX 2080均可支持SLI. 同時,RTX 2070將不支持SLI;這是與1070的背離,確實提供了.
但是,該消息的更大方面是NVIDIA專有的高速緩存連貫的GPU互連NVLINK將會使用消費卡. GeForce GTX卡將通過NVLink實現SLI,每張卡之間有2個NVLINK頻道. 在全雙工帶寬的50GB/秒組合中 – 意味著每個方向都有50GB的帶寬 – 這是對NVIDIA以前的HB-SLI鏈接的重大升級. 這是NVLink的其他功能優勢,尤其是Cache Coohrence. 所有這些都在一個重要的時刻,因為GPU間的帶寬要求不斷上升.

現在,最大的問題是,這是否會扭轉SLI的持續下降,目前我採取了某種悲觀的方法,但我渴望聽到Nvidia的更多信息. 50GB/sec比HB-SLI有很大的改進,但是它仍然僅是GPU可用的448GB/sec(或更多)本地記憶帶寬的一小部分. 因此,它本身並沒有解決纏繞多GPU渲染的問題,無論是AFR同步還是有效的工作負載分裂. 在這方面,很可能說Nvidia不支持RTX 2070上的NVLink SLI.
同時,隨著Virtuallink支持的增加,遊戲玩家可以期待VR. USB Type-C替代模式上個月宣布,支持15W以上的功率,10Gbps的USB 3.1 Gen 2數據和4個DisplayPort HBR3視頻的4個車道遍布一條電纜. 換句話說,這是DisplayPort 1.4與額外的數據和功率連接,旨在允許視頻卡直接駕駛VR耳機. 該標準由Nvidia,AMD,Oculus,Valve和Microsoft支持,因此GeForce RTX卡將是我們期望的第一款最終是支持標準的許多產品.
| USB Type-C替代模式 | ||||||
| Virtuallink | DisplayPort (4車道) | DisplayPort (2車道) | 基礎USB-C | |||
| 視頻帶寬(RAW) | 32.4Gbps | 32.4Gbps | 16.2Gbps | N/A。 | ||
| USB 3.x數據帶寬 | 10Gbps | N/A。 | 10Gbps | 10Gbps + 10Gbps | ||
| 高速車道對 | 6 | 4 | ||||
| 最大功率 | 強制性:15W 可選:27W | 可選:最多100W | ||||
最後,儘管Nvidia僅短暫涉及該主題,但我們確實知道他們的視頻編碼器nvenc已被更新用於圖靈. NVENC的最新迭代專門為8K HEVC編碼提供了支持. 同時,NVIDIA也能夠進一步調整編碼器的質量,從而使他們獲得與以前相似的質量,而視頻比特率降低了25%.